Patents

H. Phan, B. Kim, A. Bydlon, Q. Tang, C. Kao, C. Wang, V. Nguyen
Acoustic Event Detection.
P84022-US01
Page
Acoustic Event Detection.
P84022-US01
Page
R. Cohen Kadosh, T. Reed, V. Nguyen, and N. van Bueren
Method for obtaining personalized parameters for transcranial stimulation, transcranial system, method of applying transcranial stimulation.
UK Patent Application Number 2000874.4
Page
Method for obtaining personalized parameters for transcranial stimulation, transcranial system, method of applying transcranial stimulation.
UK Patent Application Number 2000874.4
Page
Publications
2026
2025
2024
Y. Liu, T. Ajanthan, H. Husain, V. Nguyen
Self-Supervision Improves Diffusion Models For Tabular Data Imputation
ACM International Conference on Information and Knowledge Management (CIKM), 2024.
Preliminary version appears at Workshop on AI4DifferentialEquations in Science, (ICLR), 2024.
Abstract PDF Code Youtube Review
Self-Supervision Improves Diffusion Models For Tabular Data Imputation
ACM International Conference on Information and Knowledge Management (CIKM), 2024.
Preliminary version appears at Workshop on AI4DifferentialEquations in Science, (ICLR), 2024.
Abstract PDF Code Youtube Review
2023
H. Husain, V. Nguyen, A. van den Hengel
Distributionally Robust Bayesian Optimization with $\varphi$-divergences
Advances in Neural Information Processing Systems (NeurIPS), 2023.
Preliminary version at Gaussian Processes, Spatiotemporal Modeling, and Decision-making Systems workshop (NeurIPS), 2022.
Abstract PDF
Distributionally Robust Bayesian Optimization with $\varphi$-divergences
Advances in Neural Information Processing Systems (NeurIPS), 2023.
Preliminary version at Gaussian Processes, Spatiotemporal Modeling, and Decision-making Systems workshop (NeurIPS), 2022.
Abstract PDF
2022
V. Nguyen, S. Farfade, A. van den Hengel
Confident Sinkhorn Allocation for Pseudo-Labeling
Preprint 2022.
Preliminary version at Distribution-Free Uncertainty Quantification workshop, ICML 2022.
Abstract PDF Code
Confident Sinkhorn Allocation for Pseudo-Labeling
Preprint 2022.
Preliminary version at Distribution-Free Uncertainty Quantification workshop, ICML 2022.
Abstract PDF Code
2021
M. Ahrens*, J. Ashwin*, J. Calliess, V. Nguyen
Bayesian Topic Regression for Causal Inference
Empirical Methods in Natural Language Processing (EMNLP), 2021.
Abstract PDF Code Long Paper
Bayesian Topic Regression for Causal Inference
Empirical Methods in Natural Language Processing (EMNLP), 2021.
Abstract PDF Code Long Paper
N. E. R. van Bueren ,T. L. Reed , V. Nguyen, J. G. Sheffield, S. H. G. van der Ven, M. A. Osborne, E. H. Kroesbergen, R. Cohen Kadosh
Personalized brain stimulation for effective neurointervention across participants
PLOS Computational Biology, 17(9), e1008886, 2021.
Abstract PDF Code Best Paper Award
Personalized brain stimulation for effective neurointervention across participants
PLOS Computational Biology, 17(9), e1008886, 2021.
Abstract PDF Code Best Paper Award


S. Kessler, V. Nguyen, S. Zohren, S. Robert
Hierarchical Indian Buffet Neural Networks for Bayesian Continual Learning
Uncertainty in Artificial Intelligence, (UAI), pp. 749-759, 2021.
Preliminary version at Bayesian Deep Learning workshop, NeurIPS 2019.
Abstract PDF Code Spotlight Presentation
Hierarchical Indian Buffet Neural Networks for Bayesian Continual Learning
Uncertainty in Artificial Intelligence, (UAI), pp. 749-759, 2021.
Preliminary version at Bayesian Deep Learning workshop, NeurIPS 2019.
Abstract PDF Code Spotlight Presentation
2020
J. Parker-Holder, V. Nguyen, S. Roberts
Provably Efficient Online Hyperparameter Optimization with Population-Based Bandits
Advances in Neural Information Processing Systems (NeurIPS), pp. 17200-17211, 2020.
Preliminary version at 7th AutoML Workshop at International Conference on Machine Learning (ICML), 2020.
Abstract PDF Code Blog Contributed Talk [3% selected]
Provably Efficient Online Hyperparameter Optimization with Population-Based Bandits
Advances in Neural Information Processing Systems (NeurIPS), pp. 17200-17211, 2020.
Preliminary version at 7th AutoML Workshop at International Conference on Machine Learning (ICML), 2020.
Abstract PDF Code Blog Contributed Talk [3% selected]
2019
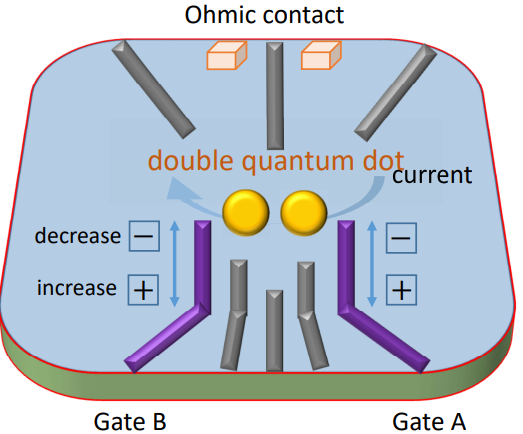
V. Nguyen, D. Lennon, H. Moon, N. Esbroeck, D. Sejdinovic, M. A. Osborne, G. A. D. Briggs, N. Ares
Controlling Quantum Device Measurement using Deep Reinforcement Learning
Deep Reinforcement Learning workshop, NeurIPS 2019.
Abstract Workshop PDF Arxiv Code
Controlling Quantum Device Measurement using Deep Reinforcement Learning
Deep Reinforcement Learning workshop, NeurIPS 2019.
Abstract Workshop PDF Arxiv Code
V. Nguyen, S. Gupta, S. Rana, M. Thai, C. Li, S. Venkatesh
Efficient Bayesian Optimization for Uncertainty Reduction over Perceived Optima Locations
Proceedings of the IEEE International Conference on Data Mining, (ICDM), pp. 1270-1275, 2019. [194/1046=18%]
Preliminary version appears at NIPS Workshop on Bayesian Optimization, (NIPSW), 2017.
Abstract PDF Code
Efficient Bayesian Optimization for Uncertainty Reduction over Perceived Optima Locations
Proceedings of the IEEE International Conference on Data Mining, (ICDM), pp. 1270-1275, 2019. [194/1046=18%]
Preliminary version appears at NIPS Workshop on Bayesian Optimization, (NIPSW), 2017.
Abstract PDF Code
2018

C. Li, S. Rana, S. Gupta, V. Nguyen, S. Venkatesh, A. Sutti, D. Rubin, T. Slezak, M. Height, M. Mohammed, and I. Gibson
Accelerating Experimental Design by Incorporating Experimenter Hunches
Proceedings of the IEEE International Conference on Data Mining, (ICDM), pp. 257-266, 2018. [84/948=9%]
Abstract PDF Code
Accelerating Experimental Design by Incorporating Experimenter Hunches
Proceedings of the IEEE International Conference on Data Mining, (ICDM), pp. 257-266, 2018. [84/948=9%]
Abstract PDF Code
2017
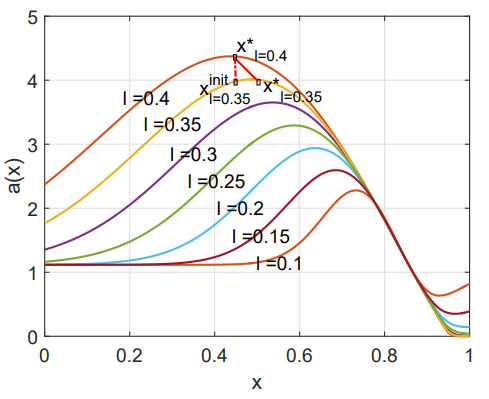
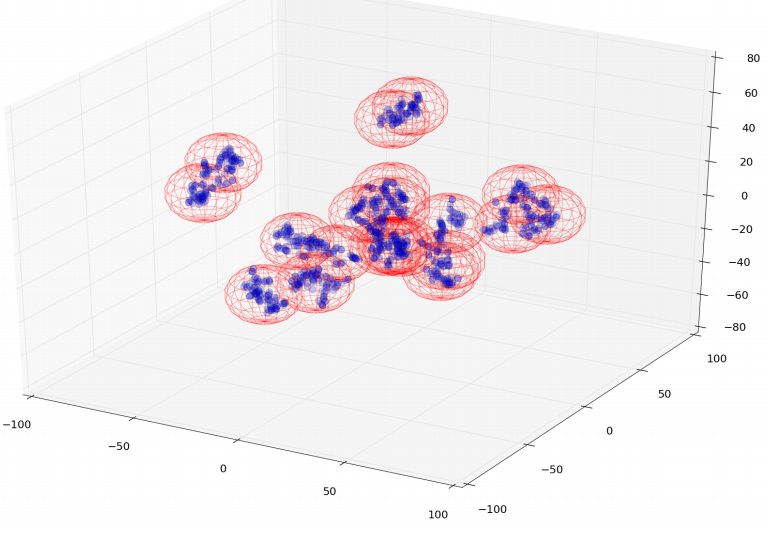
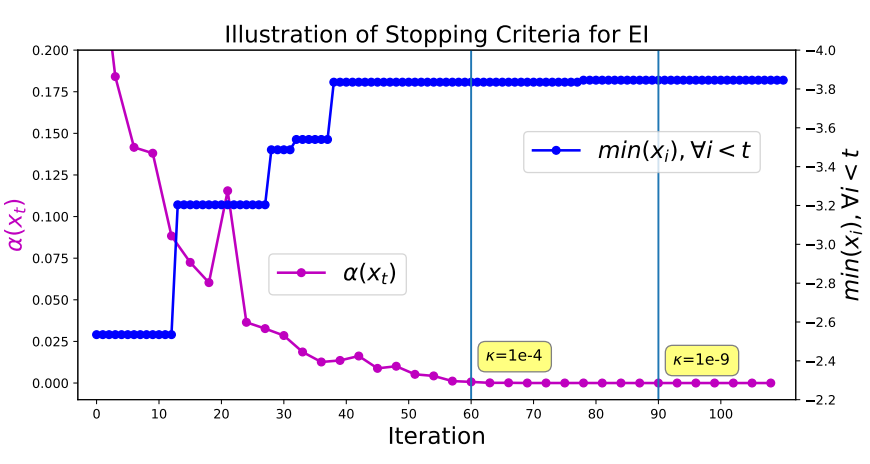
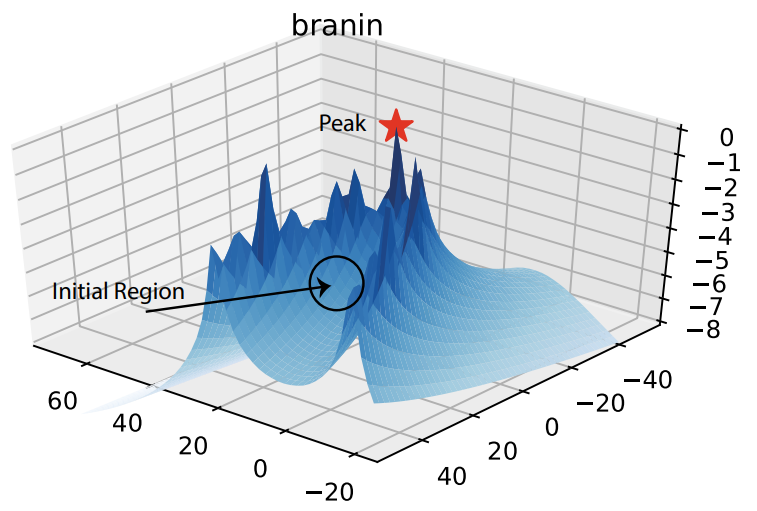
V. Nguyen, S. Gupta, S. Rana, C. Li, S. Venkatesh
Bayesian Optimization in Weakly Specified Search Space
Proceedings of the IEEE International Conference on Data Mining, (ICDM), pp 347-356, 2017. [72/778=9%]
Abstract Code Selected as Best Papers PDF Invited paper for KAIS
Bayesian Optimization in Weakly Specified Search Space
Proceedings of the IEEE International Conference on Data Mining, (ICDM), pp 347-356, 2017. [72/778=9%]
Abstract Code Selected as Best Papers PDF Invited paper for KAIS
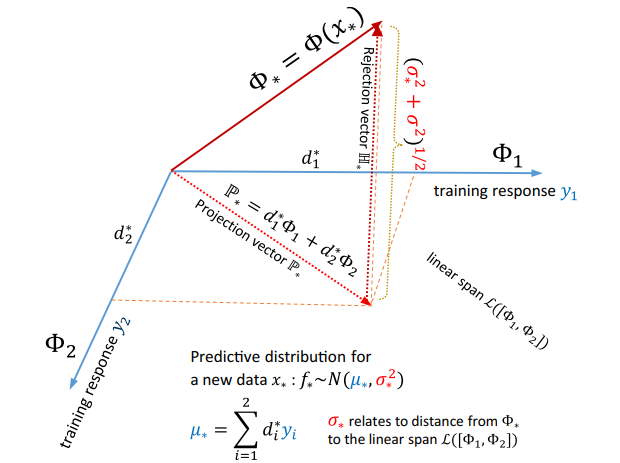
T. Le, K. Nguyen, V. Nguyen, T. D. Nguyen, D. Phung
GoGP: Fast Online Regression with Gaussian Processes
Proceedings of the IEEE International Conference on Data Mining, (ICDM), pp 257-266, 2017. [72/778=9%]
Abstract Code Selected as Best Papers PDF Invited paper for KAIS
GoGP: Fast Online Regression with Gaussian Processes
Proceedings of the IEEE International Conference on Data Mining, (ICDM), pp 257-266, 2017. [72/778=9%]
Abstract Code Selected as Best Papers PDF Invited paper for KAIS

2016 and before


V. Nguyen, S. K. Gupta, S. Rana, C. Li, S. Venkatesh
A Bayesian Nonparametric Approach for Multi-label Classification
Proceedings of The 8th Asian Conference on Machine Learning, (ACML), pp 254-269, 2016.
Abstract PDF Code Youtube Demo Best Paper Runner Up Award Best Poster Award
A Bayesian Nonparametric Approach for Multi-label Classification
Proceedings of The 8th Asian Conference on Machine Learning, (ACML), pp 254-269, 2016.
Abstract PDF Code Youtube Demo Best Paper Runner Up Award Best Poster Award






{kind=link}